轨迹记忆如何让自改进AI代理更可靠?最新ArXiv方法拆解
目录
夜里十一点,项目群里突然弹出一条消息:“回归测试又失败了,代理自己改了检索策略。” 我盯着那句日志看了许久——不是失败本身,而是它“自己改了”。它本该学习,却在偏离;它本该更聪明,却在变得不可预测。
这就是最近 AI 热点里最刺眼的一根刺:自改进代理越来越强,但可靠性却没有同步进化。 三月 ArXiv 刚发布的一篇论文《Trajectory‑Informed Memory Generation for Self‑Improving Agent Systems》试图解决这个矛盾:让代理不是“盲目改进”,而是根据历史轨迹生成可追溯记忆,再用这些记忆约束未来的改进行为。
这篇文章按“效果展示 → 问题描述 → 步骤教学 → 升华总结”的结构拆解这篇研究背后的工程意义:它为什么成为热点、解决的痛点是什么、以及你如何把它变成可落地的方法。
效果展示:当自改进代理“记得自己曾经怎么做”⌗
传统自改进代理往往只关注 “下一步能不能更好”。它会在每轮迭代中修改提示词、改写脚本或调整检索路径,却很少能回答一个关键问题:
“我为什么这样改?以前试过哪些路径?哪些失败了?”
论文提出的核心思路是:从代理的执行轨迹中生成结构化记忆。这些记忆不是随意的摘要,而是带着“因果”和“结果”的轨迹:
- 任务目标是什么
- 采取了哪些动作
- 关键节点的观察是什么
- 哪些改进有效、哪些失败
当记忆被系统化,代理的改进就不再像“临场发挥”,而更像“复盘驱动”。现实效果包括:
- 改进不再反复横跳:记忆让系统知道“曾经失败过的路径”,减少回头路。
- 评估更稳定:基于轨迹的记忆能把噪声从“评估结果”中剥离,让优化方向更一致。
- 改动更可审计:人类可以检查记忆和轨迹,理解代理为什么做出某个改动。
这就是它成为热点的原因:它不是提高一次表现,而是在提高“改进过程本身的可靠性”。
问题描述:为什么自改进代理越强越危险?⌗
很多团队发现,代理一旦进入“自改进”模式,常见问题会变得更严重:
1) 方向漂移:优化目标被“错误记忆”带偏⌗
如果代理记住了错误的策略或错误的指标,下一轮改进会沿着偏离方向加速。这就是“自我强化偏差”。
2) 评估噪声:结果不稳定导致改进路径摇摆⌗
在真实环境里,评估往往充满噪声(数据偏差、时间漂移、反馈延迟)。没有记忆的系统,只能在噪声里来回试。
3) 复盘缺位:失败没有被结构化保存⌗
失败往往是最宝贵的资产。没有可复盘的记忆,代理无法真正“从失败中学习”。
这也是为什么 “记忆”成为自改进代理的关键热点:它把改进从“盲目尝试”变成“基于轨迹的学习”。
步骤教学:如何把“轨迹记忆”变成可落地的工程流程⌗
下面这套 6 步路线,是把论文思想落地到工程系统的可操作版本:
步骤 1:明确“轨迹”记录粒度⌗
记录代理完成任务时的关键节点:
- 目标输入(用户需求、任务指标)
- 行动序列(检索、工具调用、参数变更)
- 关键观测(结果指标、错误信息)
粒度太粗会失真,太细会带来成本。
步骤 2:从轨迹中生成“结构化记忆”⌗
将轨迹压缩成可复用的记忆单元,通常包含:
- 触发条件(什么时候需要这段记忆)
- 行动路径(做了什么)
- 结果评价(成功/失败与原因)
这一步决定了记忆能否真正指导未来改进。
步骤 3:把记忆接入“自改进回路”⌗
让代理在每次改进前先检索相似记忆:
- 若存在相似失败轨迹 → 避免重复
- 若存在成功轨迹 → 复用策略
这相当于给代理加上“经验约束”。
步骤 4:建立“记忆质量评估”⌗
记忆本身也要被评估,否则错误记忆会扩散。
可行做法:
- 记忆命中后的成功率统计
- 低质量记忆自动降权/过期
步骤 5:加入“人类审核节点”⌗
对于高风险任务,必须引入人工审查:
- 抽检关键记忆
- 审核改进建议
这一步是让自改进可控的关键。
步骤 6:构建“可追溯的改进日志”⌗
让每次改进都能追溯到:
- 触发的记忆
- 采用的策略
- 结果变化
这不仅是工程要求,也是合规和治理要求。
配图:轨迹记忆如何生成与调用(论文示意图)⌗
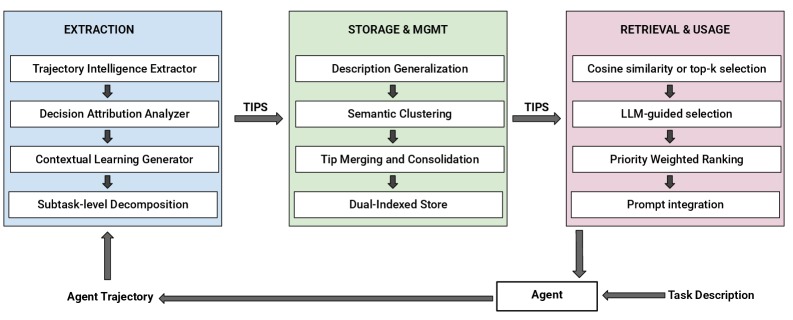
升华总结:自改进的核心不是“更聪明”,而是“更可靠”⌗
自改进代理的价值不只在于“改得快”,而在于“改得对”。轨迹记忆的价值在于把改进从“盲目试错”变成“有据可依的学习”。
如果说模型能力决定上限,那么记忆与治理决定下限。没有记忆,代理很难形成真正的“经验”;没有治理,记忆会变成偏差放大器。
真正的热点,不是模型本身,而是能否把“改进能力”变成“可靠能力”。 这也是这篇 ArXiv 研究最值得关注的原因:它不是在创造更强的 AI,而是在塑造更可控、更值得信任的 AI。
参考链接⌗
- 来源:arXiv|Trajectory-Informed Memory Generation for Self-Improving Agent Systems:https://arxiv.org/abs/2603.10600
- 来源:Fortune|AI agents are getting more capable, but reliability is lagging. And that is a problem:https://fortune.com/2026/03/24/ai-agents-are-getting-more-capable-but-reliability-is-lagging-narayanan-kapoor/
- 站点:Poorops:https://www.poorops.com/